
ลองใช้ R Language ทำ Data Visualization กันดีกว่า
เริ่มจากให้เราไป Enable Youtube API ใน google cloud platform กันมาก่อน
หลังจากเราได้ App id และ App Secret มาแล้ว เราก็เตรียมเปิด R Studio หรือ ไปสร้าง Kernal ใน Kaggle.com เพื่อทดสอบ Code R ที่เราเขียนกันฮะ ในที่นี้ผมใช้ Kaggle ที่เป็นแหล่งรวมข้อมูลของ Data Science โดยเป็นแพลตฟอร์มสำหรับ Predictive Modelling และการแข่งขันด้าน Analytics โดยมีการแข่งขันทั้งแบบบริษัท และคนปรกติทั่วไปให้เล่นและศึกษากัน
หลังจาผมไปสร้าง Account บน Kaggle แล้ว และ Create Kernels Notebook เพื่อ Run ภาษา R ก็โด้เลย
ผมใช้ 3 Library หลักๆ 3 ตัวในการเล่น ก็จะมี tuber,tidyverse และ caret
โดย tuber ผมจะใช้ในการเชื่อมต่อกับ api ของ youtube
tidyverse นั้นจะใช้ในการจัดระเบียบ data ที่ได้มา
ส่วน caret ทดสองเล่น Machine Learning ง่ายๆ
สั่ง install.packages(‘tuber’,’tidyverse’,’caret’) เสร็จแล้วก็ลอง ใช้คำสั่ง
youtube <- yt_oauth( app_id = "app_id", app_secret = "secret" )หลังจากนั้นผมก็ไปดึงข้อมูล Data จาก Channel โคตรคูล ของพี่โอ๊ต ปราโมทย์มาเล่น
khotkool_youtube_content <- get_all_channel_video_stats( channel_id = 'UC5FX2EmL4t7c305hfr-idwQ' )แล้วสั่งแสดงค่า khotkool_youtube_content ออกมา
เมื่อใช้คำสั่ง names(khotkool_youtube_content) เราจะได้ column ตามนี้
'X' 'id' 'title' 'publication_date' 'viewCount' 'likeCount' 'dislikeCount' 'favoriteCount' 'commentCount' 'url'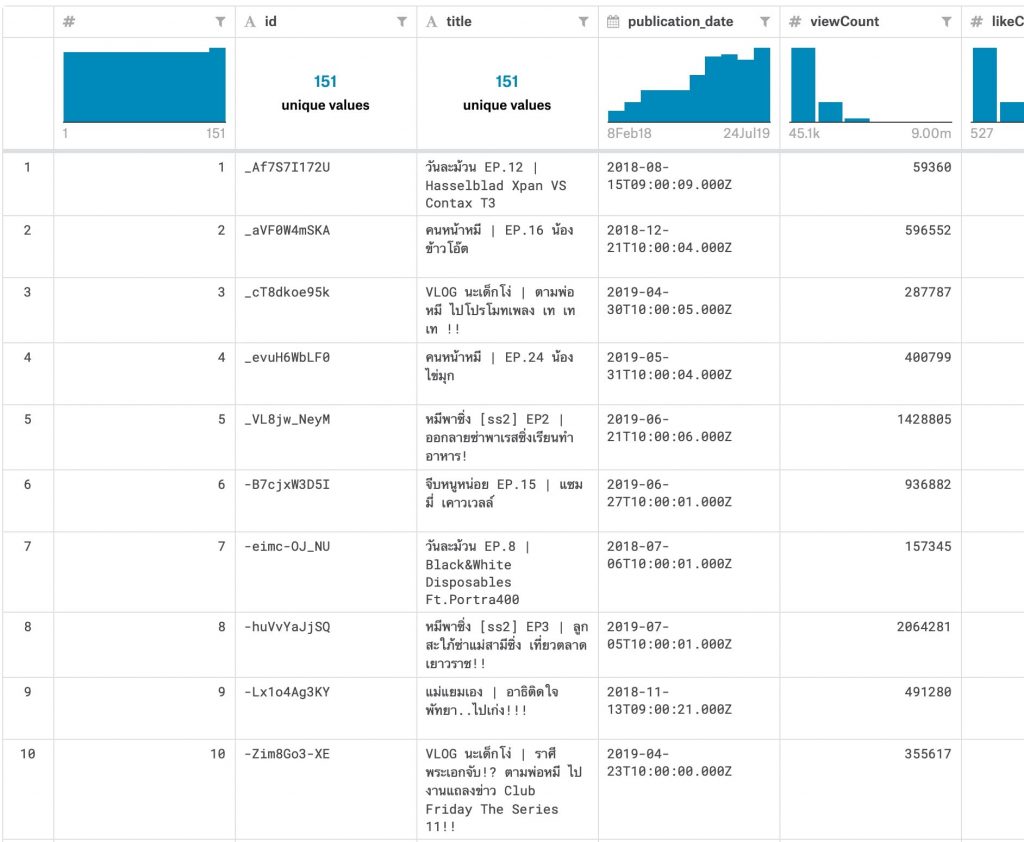
เราทำการ save data frame เราไว้ก่อนเลย ขี้เกียจโหลดใหม่ด้วยคำสั่ง
write.csv(khotkool_youtube_content,file = 'youtube.csv')หลังจากนั้นเราใช้คำสั่ง
head(khotkool_youtube_content)เพื่อแสดง 6 แถวบนสุดออกมา
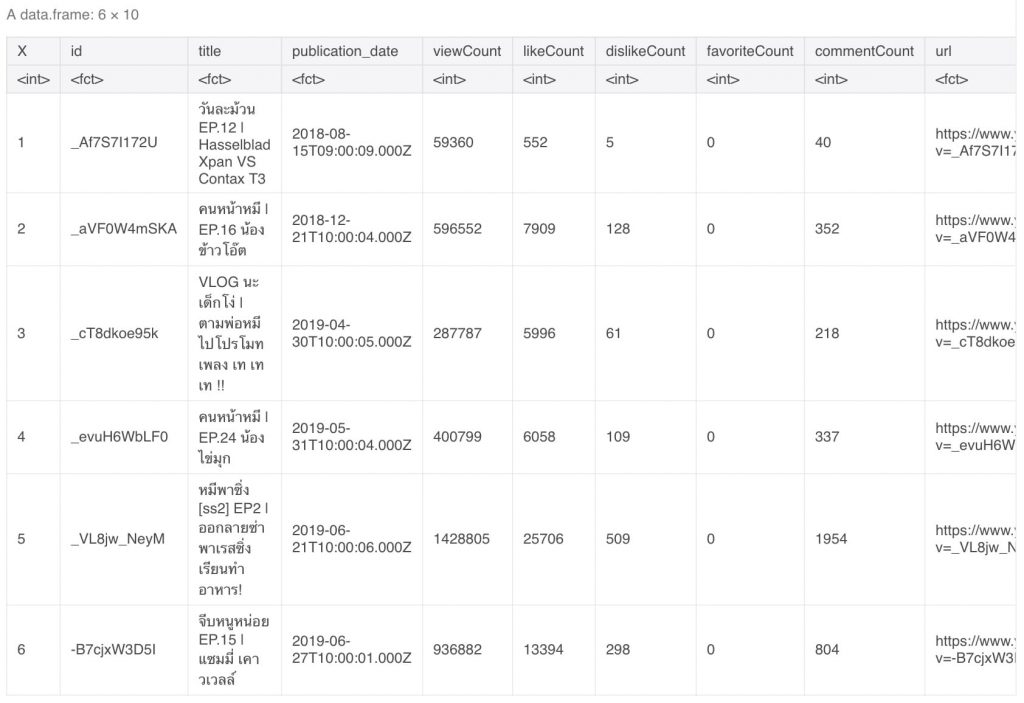
ผมใช้คำสั่ง
any(is.na(khotkool_youtube_content))เพื่อดูว่าในชุดข้อมูล 151 records มี N/A Data ปนมาหรือเปล่า
ถ้า return มาเป็น TRUE แสดงว่ามี ลบทิ้งซะเลย!!!
clean_data_khotkool <- na.omit(khotkool_youtube_content)หลังจากนั้น เช็คอีกรอบเพื่อความแน่ใจ
any(is.na(clean_data_khotkool))เย้ๆ return FALSE แล้ว
จากนั้น ผมใช้ tidyverse pipe จัดการชุดข้อมูลแยกตามรายการที่อยู่ใน โคตรคูล Channel กันทีละอัน เบื้องต้นคงเก็บไว้แค่ title viewCount likeCount dislikeCount commentCount url ตัดพวกวันที่ออก ไม่รู้จะเอาไปไร
โดยผมจะ fileter รายการทั้งหมด detect ที่ title ที่มีคำว่า หมีพาซิ่ง ออกมาก่อน แล้วจาก แล้วสร้าง group เพื่อระบุว่า content นี้เป็นข้อมูลชุดไหนใน Channel แล้วเก็บไว้ที่ตัวแปร mee_pa_zine
clean_data_khotkool %>% filter(str_detect(title,'หมีพาซิ่ง')) %>% select(X,title,viewCount,likeCount,dislikeCount,commentCount,url) %>% mutate(content_group = "mee_pa_zine") -> mee_pa_zineหลังจากนั้นจึงสั่ง head ออกมา 6 แถว เช็คดู
head(mee_pa_zine)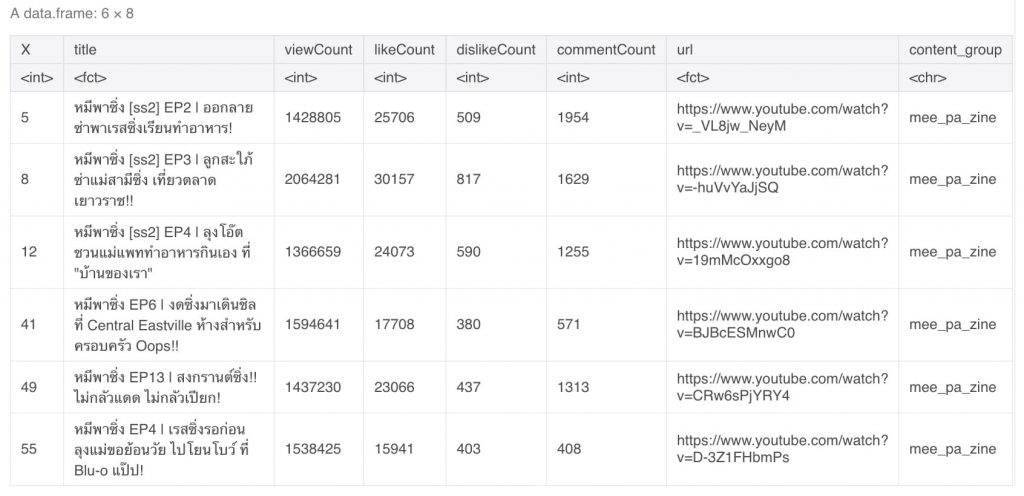
หลังจากนั้นก็แยกออกมันทุกรายการเลยทั้ง หมีพาซิ่ง vlog แม่แยมเอง…จนจีบหนูหน่อย
แล้วเอาทุก data frame มา combine กันเป็นข้อมูลชุดเดียวกันใหม่
all_content_channel <- rbind(mee_pa_zine,one_la_muan,jeep_nu_noi,vlog,mae_yam_eang,khon_na_mee)หลังจากนั้นเลยใช้ tidyverse จัดรูปแบบร่วมกับ ggpolt มาเป็นกราฟว่ารายการไหนในช่อง มีคนดูเยอะสุดๆ
all_content_channel %>% group_by(content_group) %>% summarise(mostViews = sum(viewCount)) %>% arrange(desc(mostViews)) %>% ggplot(.,mapping = aes( x=reorder(content_group,-mostViews), y=mostViews/1000)) + geom_col(col = "red", fill = "orange", alpha = 0.7) + coord_flip() + labs(x = "Content Name", y = "Total Views x 1000")ลำดับรายการที่มียอดวิว มากที่สุดได้แก่รายการรรรรรรร หมีพาซิ่งครับ ซิ่งมียอดวิวมากถึง 30 กว่าล้านยอดวิว หมีพาซิ่งมี 18 คลิป vlog มี 32 คลิป จีบหนูหน่อย 17 คลิป คนหน้าหมี 27 คลิป แม่แยมเอง 21 คลิป วันละม้วน 21 คลิป
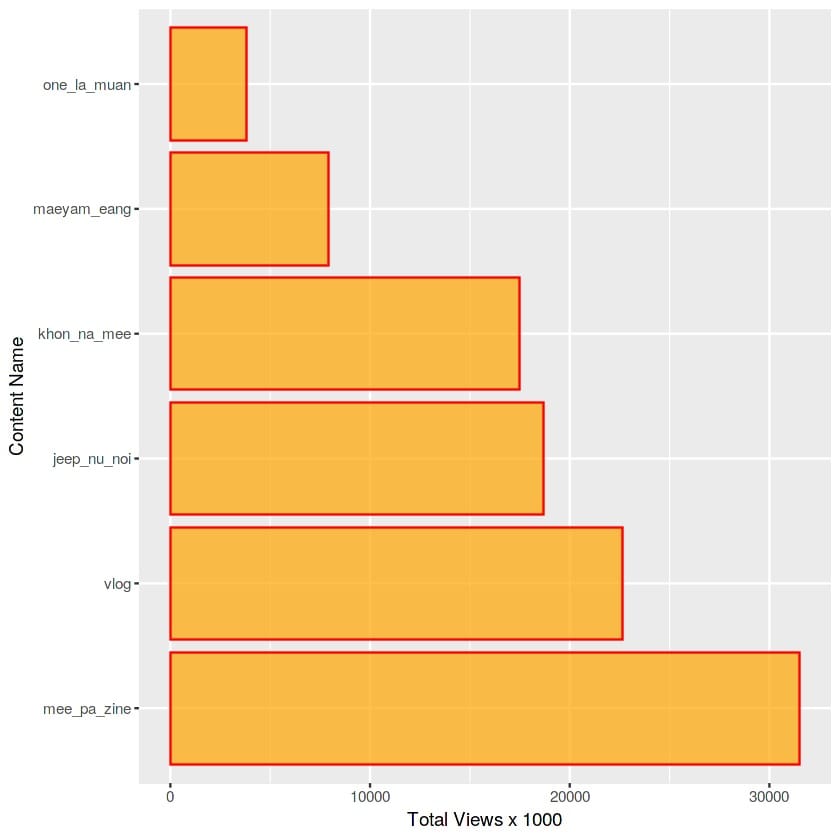
โอ้โห เพิ่งรู้ว่า ภาษา R ทำให้เรา จะการ Data ออกมาในรูปแบบการนำเสนอที่สวยงาม และน่าสนใจเข้าใจง่ายมากๆ แต่ผมไม่ได้มาสายนี้ ยังนึกไม่ออกว่าจะเอาไปทำอะไรต่อดี อันนี้แค่ซนเล่นๆ
สักพักกำลังเขียนดึง youtube เล่นๆ ก็ไปเจอน้องในทีมกำลังนั่ง plot ค่า อุณหภูมิของ Hardware ใน Project หน่ึง ลง Excel เพื่อ ทำ heatmap ส่ง report ลูกค้า
โดยหาค่าเฉลี่ยยในรอบชั่วโมง แล้วนำมากำหนดสี ทำวนๆไป ทุกอาทิตย์ ทุกเดือน ช่างซ้ำซ้อนเปลืองแรงยิ่งนัก
เลยขอ Excel มาลอง เขียน Code ด้วย R แล้ว process เป็น heatmap ให้
ปรากฏว่าง่ายกับชีวิตมาก ใช้เวลาไม่ถึง 15 นาทีก็เรียบร้อย
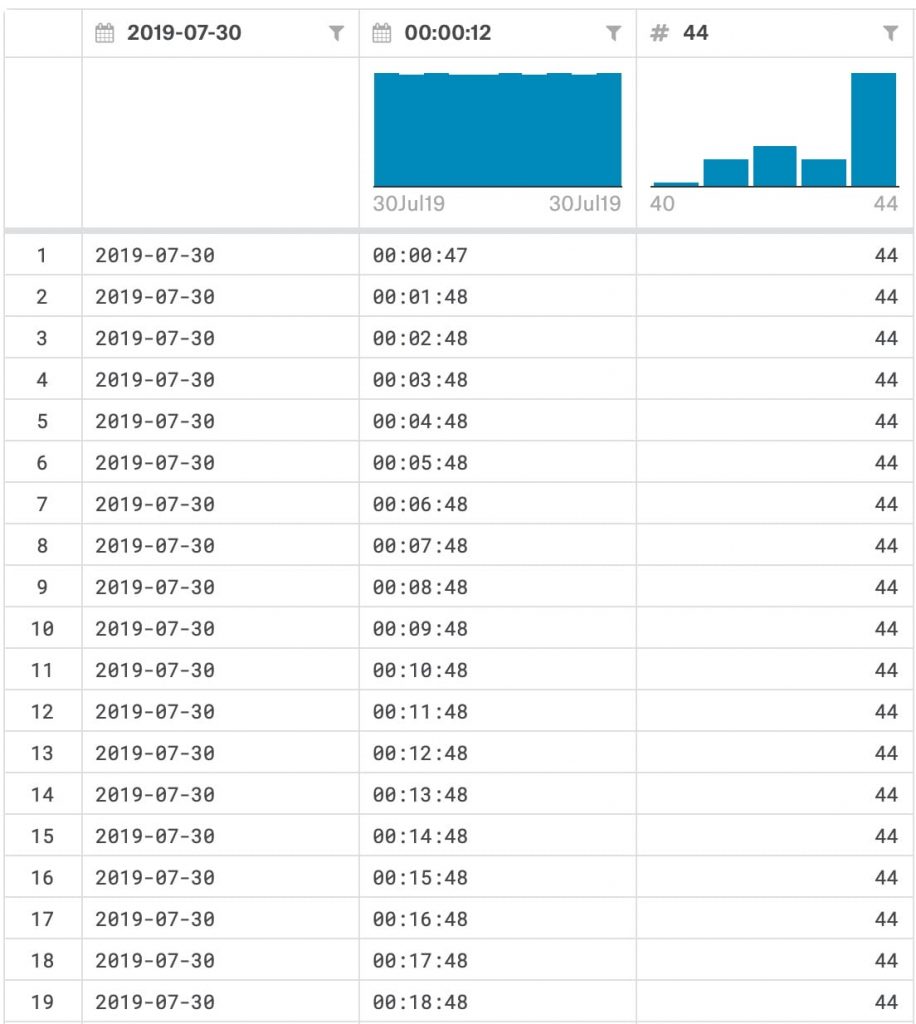
โดยข้อมูลใน Excel เป็นแบบนี้
จะเห็นว่า log reader มีการอ่านค่ามาทุกวินาทีเลยว่าอุณหภูมิของ reader ตอนนี้เท่าไหร่แล้ว
โจทย์คือน้องในทีมต้องการแค่ค่า avg ของแต่ละชั่วโมงแค่นั้นพอ
Library ที่เราใช้ก็มีแค่
library(tidyverse)library(lubridate)library(anytime)หลังจากนั้นก็อ่าน Data frame มาเก็บไว้ที่ temperature
temperature <- read.csv(file = '../input/Temp-30-07-2019-WH.csv')อย่าลืมเช็ค Missing Data และ ดู column ว่ามีอะไรบ้าง
names(temperature)any(is.na(temperature))ผลคือมี column ดังนี้
‘X2019.07.30’
‘X00.00.12’
‘X44’
ผมเอา column วันที่กับ เวลารวมกัน เพื่อจะ group data frame ออกมาเป็น รายชั่วโมงแล้วหาค่า avg
clean_temp <- unite_(temperature,"Date",c("X2019.07.30","X00.00.12"))head(clean_temp)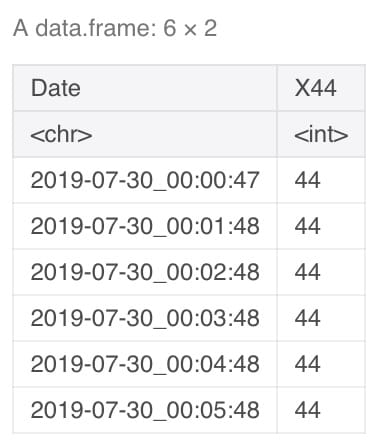
หลังจากนั้นจัดการเพิ่ม column แยกชั่วโมงออกมาจาก column Date เพื่อที่จะบอกว่า record นั้น อยู่ในชั่วโมงที่เท่าไหร่
clean_temp %>%mutate(Date = ymd_hms(Date),day = floor_date(Date,'day'),hour = hour(Date)) -> build_datanames(build_data)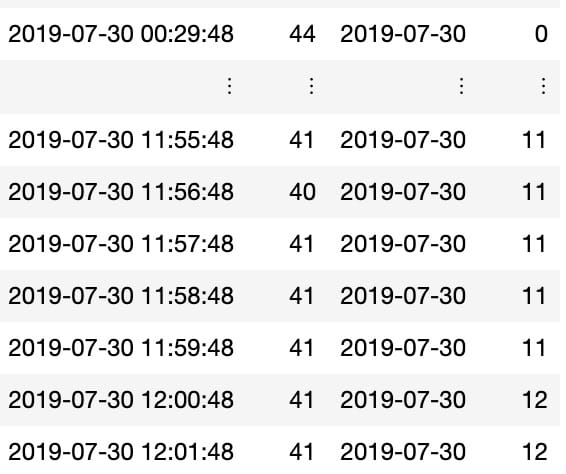
เสร็จแล้วก็มา plot heatmap ด้วย ggplot เพื่อแสดงอุณหภูมิของ Hardware ที่เกิดขึ้นในแต่ละชั่วโมงที่มีการใช้งานด้วย การ group by ชั่วโมง แล้วหาค่า mean ของ column อุณหภูมิ
build_data %>%group_by(hour) %>%summarise(temperature = mean(X44)) %>%ggplot(.,aes(x = hour, y = 1))+geom_tile(aes(fill = temperature)) +scale_fill_gradient(low = "orange", high = "red") +labs(y = NULL) +scale_y_continuous(breaks = NULL)ชะแว้ปปปป
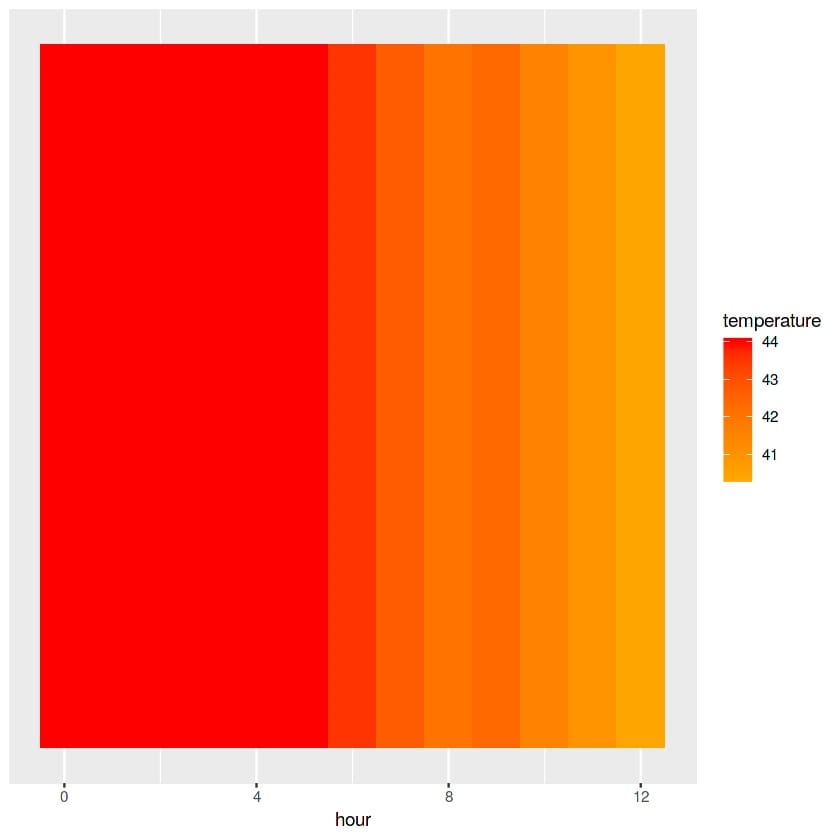
ของเล่นเยอะจริงๆกับ ภาษา R เนี่ย
เขียนก็ง่ายกว่า SQL จัดการข้อมูล จบในภาษาเดียวได้เลย ชอบๆ
ส่วน code ของ 2 ตัวนี้ ไปดูเต็มๆกันได้ที่
https://www.kaggle.com/aofiee/khotkool-youtube-channel
และ
https://www.kaggle.com/aofiee/heatmap-from-rfid-reader
ขอบคุณครับ